
 by
by Pada artikel ini akan dilakukan proses mengelola data kapal Titanic. Proses pengelolaannya, pertama adalah melakukan drop pada kolom yang dinilai tidak memiliki pengaruh pada proses berikutnya. Kedua, mengisi data yang kosong dan yang terakhir adalah mengelompokkan data yang ada. Proses ini merupakan kelanjutan dari artikel Belajar Data Science – Visualisasi Data Penjualan dan Belajar Data Science – Visualisasi Data Histogram – Mengeksplorasi Data Kapal Titanic (Bagian 2). Data kapal Titanic dapat di akses melalui situs Kaggle.
Import Pustaka
Melakukan import pustaka yang dibutuhkan yaitu pandas dan numpy.
import pandas as pd
import numpy as npMengambil data
Data akan diambil dari github yang disiapkan oleh tim Onestring Lab. Data akan disimpan dalam bentuk Pandas dataframe. Penjelasan mengenai Pandas dataframe dapat dipelajari pada bagian Data Science. Berikut ini kode program untuk mengambil data dari github Onestring Lab. Data yang akan digunakan adalah data train.csv dan test.csv.
train_df = pd.read_csv('https://raw.githubusercontent.com/Onestringlab/osl_datascience/main/data/titanic/train.csv')
train_df.head()
test_df = pd.read_csv('https://raw.githubusercontent.com/Onestringlab/osl_datascience/main/data/titanic/test.csv')
test_df.head()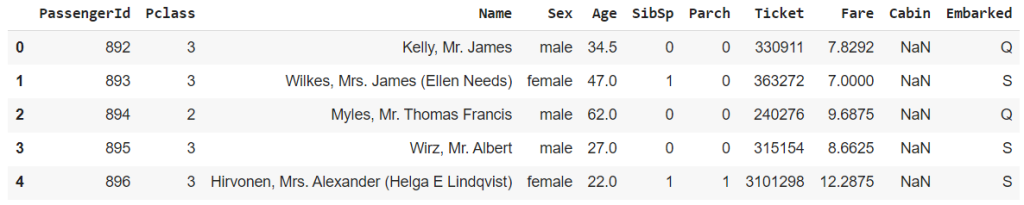
Menghapus Beberapa Kolom Data
Pada data kapal Titanic terdapat beberapa kolom yang perlu dihilangkan. Ini dikarenakan data tersebut bersifat unik. Kolom data tersebut adalah Passenger Id, Name, Ticket dan Cabin.
train_df['Ticket'].describe()Terlihat bahwa dari 891 data terdapat 681 data unik.
count 891
unique 681
top 347082
freq 7
Name: Ticket, dtype: objectBerikut ini adalah perintah drop untuk beberapa kolom tersebut.
train_df = train_df.drop(['Ticket'], axis=1)
test_df = test_df.drop(['Ticket'], axis=1)
train_df = train_df.drop(['PassengerId'], axis=1)
test_df = test_df.drop(['PassengerId'], axis=1)
train_df = train_df.drop(['Name'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
train_df = train_df.drop(['Cabin'], axis=1)
test_df = test_df.drop(['Cabin'], axis=1)Mengecek Data Yang Hilang
Berikut ini adalah proses untuk mengetahui data mana saja yang hilang.
row = train_df.shape[0]
total = train_df.isnull().sum().sort_values(ascending=False)
presentase = ((train_df.isnull().sum()/row)*100).sort_values(ascending=False)
presentase = round(presentase,2)
dt_missing = list(zip(total,presentase))
train_df_missing = pd.concat([total,presentase],axis=1,keys=['Total','%'])
train_df_missing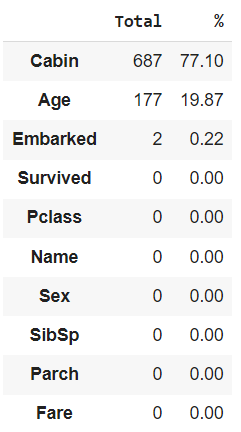
Menggabungan Data Train dan Test
Berikut ini akan menggabungkan data Train dan Test dalam bentuk array.
data = [train_df,test_df]Mengisi Data Kosong Pada Kolom Age
Untuk data kosong pada kolom Age akan diisi angka random diantara mean – stdeviasi dan mean+ stdeviasi. Berikut ini kode programnya.
train_df['Age'].isnull().sum()
for dataset in data:
mean = train_df['Age'].mean()
std = train_df['Age'].std()
is_null = dataset['Age'].isnull().sum()
rand_age = np.random.randint(mean-std,mean+std, size= is_null)
age_slice = dataset['Age'].copy()
age_slice[np.isnan(age_slice)] = rand_age
dataset['Age'] = age_slice
dataset['Age'] = train_df['Age'].astype(int)
train_df['Age'].isnull().sum()Mengisi Data Kosong Pada Kolom Embarked
Untuk data kosong pada kolom Embarked akan diisi dengan huruf ‘S’ dikarenakan data tersebut paling banyak pada kolom tersebut. Berikut ini kode programnya.
for dataset in data:
dataset['Embarked'] = dataset['Embarked'].fillna('S')Mengisi Data Kosong Pada Kolom Fare
Untuk data kosong pada kolom Fare akan diisi dengan angka 0. Berikut ini kode programnya.
for dataset in data:
dataset['Fare'] = dataset['Fare'].fillna(0)
dataset['Fare'] = dataset['Fare'].astype(int)
Mengubah Data Pada Kolom Sex dan Embarked
Proses pembelajaran machine learning hanya mengenal angka. Ini mengharuskan melakukan perubahan data string kedalam bentuk bilangan. Kolom Sex yang berisi male dan female akan diubah kedalam bentuk 1 dan 2. Sedangkan kolom Embarked S, C dan Q berubah menjadi 0,1 dan 2. Berikut ini kode programnya.
genders = {"male" : 0, "female" :1}
for dataset in data:
dataset['Sex'] = dataset['Sex'].map(genders)ports = {"S":0, "C":1, "Q":2}
for dataset in data:
dataset['Embarked'] = dataset['Embarked'].map(ports)Mengompokan Data Kolom Age
Data pada kolom Age sifatnya hampir mendekati unik. Ini kurang baik untuk proses pembelajaran. Hal yang harus dilakukan adalah mengelompokkkanya dalam bentuk range umur. Pada kolom Fare juga akan dilakukan proses yang sama. Berikut ini kode programnya.
for dataset in data:
dataset['Age'] = dataset["Age"].astype(int)
dataset.loc[dataset['Age'] <=11, 'Age']=0
dataset.loc[(dataset['Age'] >11) & (dataset['Age'] <=18), 'Age']=1
dataset.loc[(dataset['Age'] >18) & (dataset['Age'] <=22), 'Age']=2
dataset.loc[(dataset['Age'] >22) & (dataset['Age'] <=27), 'Age']=3
dataset.loc[(dataset['Age'] >27) & (dataset['Age'] <=33), 'Age']=4
dataset.loc[(dataset['Age'] >33) & (dataset['Age'] <=40), 'Age']=5
dataset.loc[(dataset['Age'] >40) & (dataset['Age'] <=66), 'Age']=6
dataset.loc[(dataset['Age'] >66), 'Age']=6for dataset in data:
dataset.loc[dataset['Fare'] <=7.91, 'Fare']=0
dataset.loc[(dataset['Fare'] >=7.91) & (dataset['Fare'] <=14.454), 'Fare']=1
dataset.loc[(dataset['Fare'] >14.454) & (dataset['Fare'] <=31), 'Fare']=2
dataset.loc[(dataset['Fare'] >31) & (dataset['Fare'] <=99), 'Fare']=3
dataset.loc[(dataset['Fare'] >99) & (dataset['Fare'] <=250), 'Fare']=4
dataset.loc[dataset['Fare'] >250, 'Fare']=5Membuat Kolom Baru
Untuk proses machine learning dinilai perlu membuat kolom baru yang merupakan hasil kombinasi dari kolom yang sudah ada. Berikut ini kode programnya.
for dataset in data:
dataset['relatives'] = dataset['SibSp'] + dataset['Parch']
dataset.loc[dataset['relatives'] > 0, 'not_alone'] = 0
dataset.loc[dataset['relatives'] == 0, 'not_alone'] = 1
dataset['not_alone'] = dataset['not_alone'].astype(int)for dataset in data:
dataset['Age_Class'] = dataset['Age'] * dataset['Pclass']for dataset in data:
dataset['Fare_Per_Person'] = dataset['Fare']/(dataset['relatives']+1)
dataset['Fare_Per_Person'] = dataset['Fare_Per_Person'].astype(int)Hasil Preprocessing Data Kapal Titanic
Berikut ini adalah hasil data terakhir setelah dilakukan proses manipulasi.
train_df.head(10)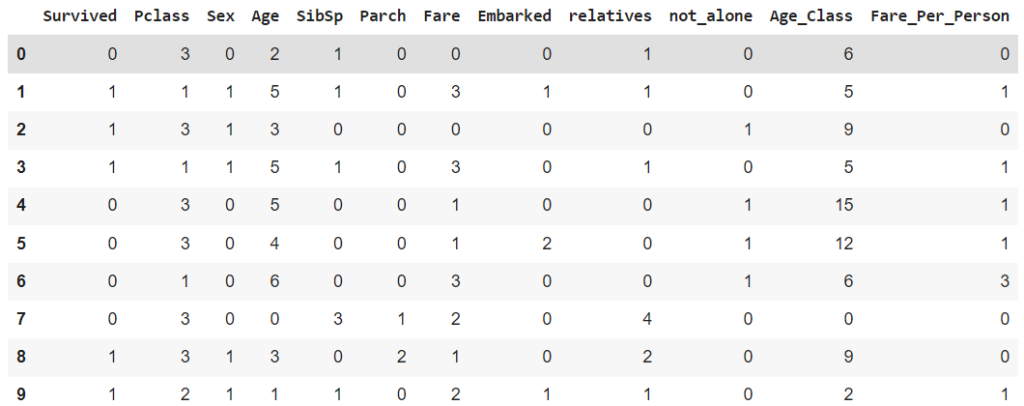
test_df.head(10)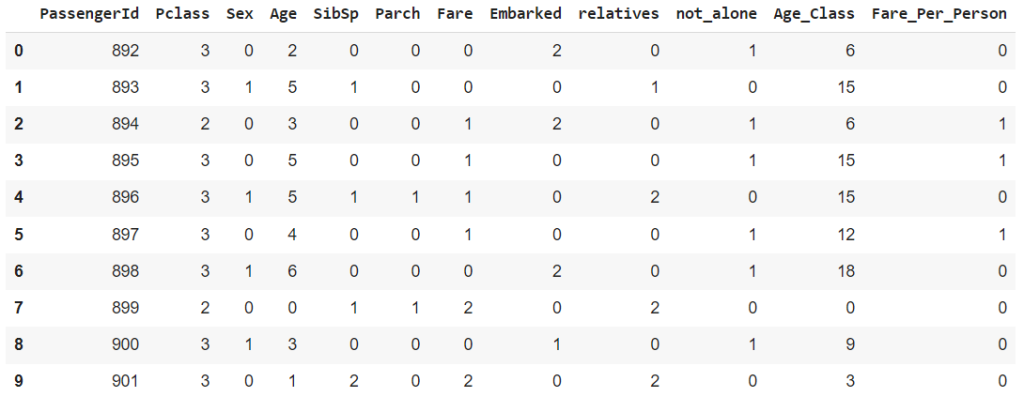
Kesimpulan Preprocessing Data Kapal Titanic
Proses pengelolaan data merupakan hal terpenting sebelum dilakukan proses pembelajaran. Jika proses ini tidak dilakukan dengan benar dan tepat maka proses pembelajaran tidak ada menghasilkan model yang baik dan bisa digunakan.



